ALTER TABLE olist_order_payments_dataset MODIFY payment_value DECIMAL(10,2), MODIFY payment_installments INT;
2.3 处理重复数据
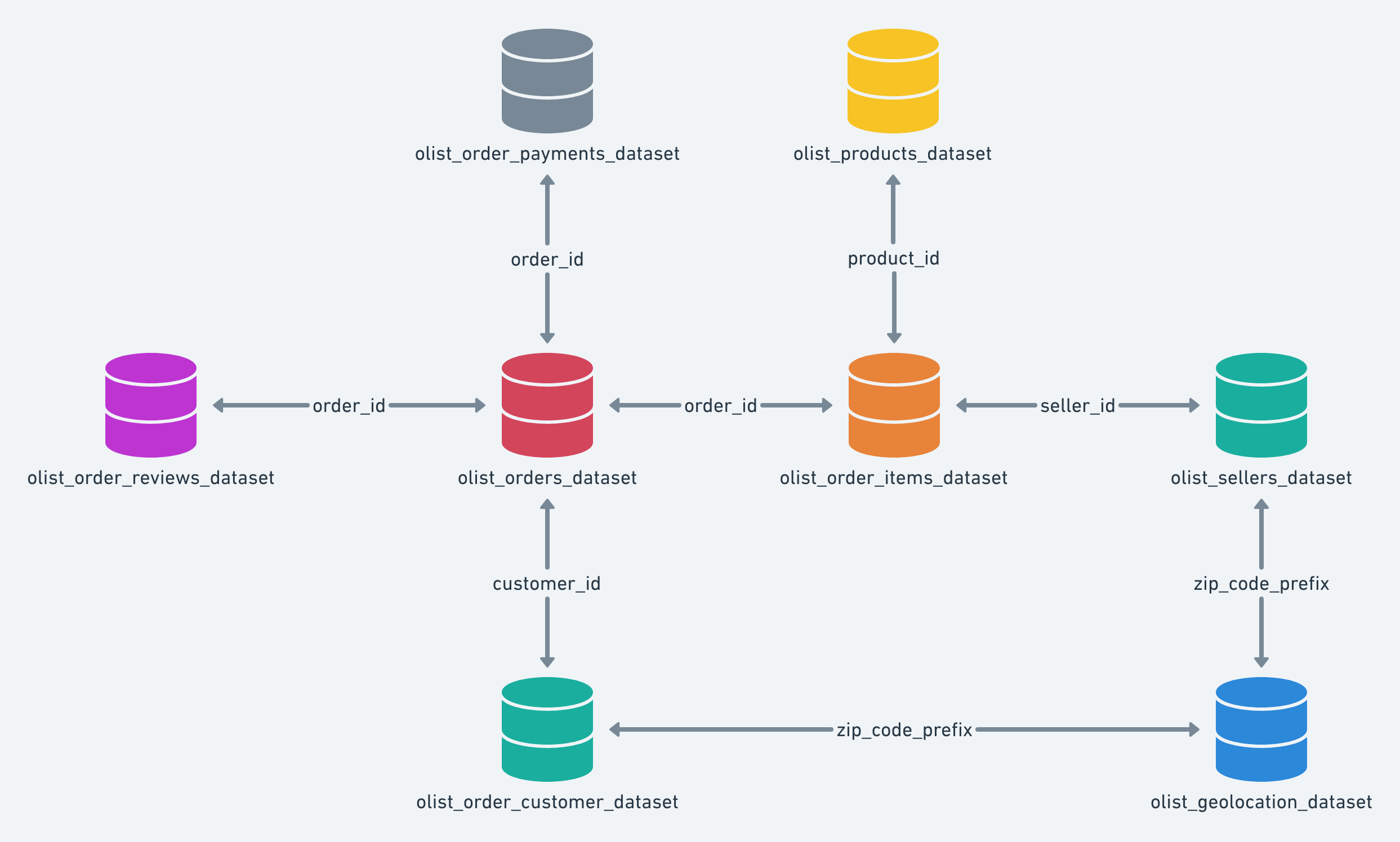
问题:geolocation表一个邮编对应多个经纬度坐标(每次下单记录的定位略有不同)
解决方案:按邮编分组,取平均经纬度
1 2 3 4 5 6 7 8 9 10 11 12 13
-- 创建临时表存储去重后的地理位置 CREATE TABLE geolocation_clean AS SELECT geolocation_zip_code_prefix, ROUND(AVG(geolocation_lat), 7) as lat, ROUND(AVG(geolocation_lng), 7) as lng, MAX(geolocation_city) as city, MAX(geolocation_state) as state FROM olist_geolocation_dataset GROUPBY geolocation_zip_code_prefix;
-- 添加索引加速查询 CREATE INDEX idx_zip ON geolocation_clean(geolocation_zip_code_prefix);
-- 查看各表缺失情况 SELECT COUNT(*) as total, COUNT(order_delivered_customer_date) as delivered_count, COUNT(*) -COUNT(order_delivered_customer_date) as missing_count FROM olist_orders_dataset;
UPDATE olist_orders_dataset SET purchase_date =DATE(order_purchase_timestamp), purchase_hour =HOUR(order_purchase_timestamp);
-- 创建索引加速时间查询 CREATE INDEX idx_date ON olist_orders_dataset(purchase_date); CREATE INDEX idx_hour ON olist_orders_dataset(purchase_hour);
三、核心业务指标分析
3.1 用户地域分布
问题:用户主要分布在巴西哪些地区?
1 2 3 4 5 6 7 8 9 10
-- 各州用户数量分布 SELECT c.customer_state as 州, COUNT(DISTINCT c.customer_unique_id) as 用户数, ROUND(COUNT(DISTINCT c.customer_unique_id) *100.0/ SUM(COUNT(DISTINCT c.customer_unique_id)) OVER(), 2) as 占比 FROM olist_customers_dataset c GROUPBY c.customer_state ORDERBY 用户数 DESC LIMIT 10;
查询结果:
州
用户数
占比
SP
41,746
43.42%
RJ
12,852
13.37%
MG
11,627
12.10%
RS
5,466
5.69%
PR
5,045
5.25%
关键发现:
43%的用户来自SP州(圣保罗州),这是巴西人口最多、经济最发达的州
**前三个州(SP+RJ+MG)占比近70%**,集中在东南部沿海
这与巴西人口分布和经济发达程度高度一致
业务建议:
重点在SP州投入营销资源
北部和东北部用户较少,有增长空间
3.2 用户活跃度分析(DAU/MAU)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
-- 日活跃用户数(DAU)趋势 SELECT purchase_date as 日期, COUNT(DISTINCT c.customer_unique_id) as DAU, COUNT(*) as 订单数 FROM olist_orders_dataset o JOIN olist_customers_dataset c ON o.customer_id = c.customer_id GROUPBY purchase_date ORDERBY purchase_date;
-- 月活跃用户数(MAU) SELECT DATE_FORMAT(purchase_date, '%Y-%m') as 月份, COUNT(DISTINCT c.customer_unique_id) as MAU FROM olist_orders_dataset o JOIN olist_customers_dataset c ON o.customer_id = c.customer_id GROUPBY DATE_FORMAT(purchase_date, '%Y-%m') ORDERBY 月份;
关键发现:
DAU总体呈上升趋势
**2017年11月24日DAU暴增327%**,这是”黑色星期五”促销活动的效果
2017年11月后MAU趋于平稳,说明平台进入成熟期
3.3 用户下单时间偏好
1 2 3 4 5 6 7 8
-- 24小时下单分布 SELECT purchase_hour as 小时, COUNT(*) as 订单数, ROUND(COUNT(*) *100.0/SUM(COUNT(*)) OVER(), 2) as 占比 FROM olist_orders_dataset GROUPBY purchase_hour ORDERBY purchase_hour;
查询结果分析:
时间段
订单占比
特点
0-6点
7.2%
深夜,订单最少
6-12点
32.1%
上午,订单快速增长
12-18点
38.5%
下午,订单最高峰
18-22点
22.3%
晚间,订单逐渐减少
关键发现:
用户全天都在下单,不受上班时间影响
中午12点和下午6点略有下降(饭点)
晚上10点后明显下降
业务建议:
促销活动安排在上午10点到晚上10点
客服值班重点安排在高活跃时段
3.4 支付方式分析
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
-- 支付方式偏好 SELECT payment_type as 支付方式, COUNT(DISTINCT order_id) as 订单数, ROUND(COUNT(DISTINCT order_id) *100.0/ SUM(COUNT(DISTINCT order_id)) OVER(), 2) as 占比 FROM olist_order_payments_dataset GROUPBY payment_type ORDERBY 订单数 DESC;
-- 信用卡分期情况 SELECT payment_installments as 分期数, COUNT(*) as 订单数, ROUND(COUNT(*) *100.0/SUM(COUNT(*)) OVER(), 2) as 占比 FROM olist_order_payments_dataset WHERE payment_type ='credit_card' GROUPBY payment_installments ORDERBY 分期数;
关键发现:
73.9%的订单使用信用卡支付
19.7%使用boleto(巴西本地线下支付方式)
超过65%的信用卡订单选择分期付款(1-10期为主)
说明巴西消费者习惯分期消费
3.5 用户评分分析
1 2 3 4 5 6 7 8 9
-- 评分分布 SELECT review_score as 评分, COUNT(*) as 评价数, ROUND(COUNT(*) *100.0/SUM(COUNT(*)) OVER(), 2) as 占比 FROM olist_order_reviews_dataset WHERE review_score ISNOT NULL GROUPBY review_score ORDERBY 评分 DESC;
-- 步骤1:创建订单明细视图(整合订单+客户+支付) CREATEVIEW order_detail AS SELECT o.order_id, o.purchase_date, c.customer_unique_id, SUM(p.payment_value) as payment_value FROM olist_orders_dataset o JOIN olist_customers_dataset c ON o.customer_id = c.customer_id JOIN olist_order_payments_dataset p ON o.order_id = p.order_id WHERE o.order_status ='delivered'-- 只统计已送达订单 GROUPBY o.order_id, o.purchase_date, c.customer_unique_id;
-- 步骤2:计算每个客户的RFM值 WITH rfm_base AS ( SELECT customer_unique_id, -- R值:最近一次购买距今天数(越小越好) DATEDIFF('2018-10-18', MAX(purchase_date)) as recency, -- F值:购买次数 COUNT(DISTINCT order_id) as frequency, -- M值:总消费金额 SUM(payment_value) as monetary FROM order_detail GROUPBY customer_unique_id ) SELECT*FROM rfm_base LIMIT 10;
-- 创建RFM分层视图 CREATEVIEW rfm_segment AS WITH rfm_base AS ( SELECT customer_unique_id, DATEDIFF('2018-10-18', MAX(purchase_date)) as recency, COUNT(DISTINCT order_id) as frequency, SUM(payment_value) as monetary FROM order_detail GROUPBY customer_unique_id ), rfm_score AS ( SELECT customer_unique_id, recency, frequency, monetary, -- R评分:高于均值(recency大)= 0,低于均值(recency小)= 1 CASEWHEN recency <= (SELECTAVG(recency) FROM rfm_base) THEN1ELSE0ENDas R, -- F评分:高于均值 = 1,低于均值 = 0 CASEWHEN frequency >= (SELECTAVG(frequency) FROM rfm_base) THEN1ELSE0ENDas F, -- M评分:高于均值 = 1,低于均值 = 0 CASEWHEN monetary >= (SELECTAVG(monetary) FROM rfm_base) THEN1ELSE0ENDas M FROM rfm_base ) SELECT customer_unique_id, recency, frequency, monetary, R, F, M, CONCAT(R, F, M) as rfm_code, -- 客户分层 CASE WHEN R=1AND F=1AND M=1THEN'重要价值客户' WHEN R=1AND F=0AND M=1THEN'重要发展客户' WHEN R=0AND F=1AND M=1THEN'重要保持客户' WHEN R=0AND F=0AND M=1THEN'重要挽留客户' WHEN R=1AND F=1AND M=0THEN'一般价值客户' WHEN R=1AND F=0AND M=0THEN'一般发展客户' WHEN R=0AND F=1AND M=0THEN'一般保持客户' WHEN R=0AND F=0AND M=0THEN'一般挽留客户' ENDas 客户类型 FROM rfm_score;
-- 查看各类型客户数量和贡献 SELECT 客户类型, COUNT(*) as 客户数, ROUND(COUNT(*) *100.0/SUM(COUNT(*)) OVER(), 2) as 客户占比, ROUND(SUM(monetary), 2) as 总消费额, ROUND(SUM(monetary) *100.0/SUM(SUM(monetary)) OVER(), 2) as 销售额贡献, ROUND(AVG(monetary), 2) as 客单价, ROUND(AVG(recency), 0) as 平均最近购买天数, ROUND(AVG(frequency), 1) as 平均购买次数 FROM rfm_segment GROUPBY 客户类型 ORDERBY 总消费额 DESC;